


不要告诉别人(抠一下是什么意思)抠chi,抠一下chatgpt的技术细节,


序言
做了好多年的chatbot,从日语的rinna到英文JAXP,一开始对chatgpt的出现,啥有一些相冲突,觉得这玩意是一分钟关注度,迅速就会被我们委身于武林。
无可奈何,贴文被刷爆了,他们也禁不住注册登记了一个帐户,怎么说呢:


我喂了chatgpt两个对我的工作有象征意义的难题:
难题一:给我M511RDnvidia nemo和hugging face transformers的差别。【因为JURLIQUEnvidia nemo的这时候,浑然不觉天神跳脱而言,俺有hugging face的transformers,要你nemo多难?水族吗?!】
虽说,那个提问,我他们都没用。。。要不然,就觉得之后再JURLIQUEnvidia nemo的这时候,有诚意了。
也是说,nvidia nemo是用以做谈话AI的(安心,chatgpt先期会有听觉和感官的护持的,因此多逻辑控制系统谈话控制系统大有作为),而hugging face家的transformers是搞预体能训练nlp (只不过也有asr, tts)的“采用网络平台”。
难题二:在韩国怎样图利。

译者回来是:
在韩国有多种不同图利形式,包括:
1 借助税赋免收 - 韩国有很多免收能增加您的增值税总收入,比如计入亲属,医疗保健服务费和对慈善组织机构的捐助。
2 向税延卸任帐户缴税 - 通过向税延卸任帐户(比如 401(k) 或 NISA)缴税,您能增加增值税总收入并为未来的卸任储蓄。
3 进行慈善捐赠 - 对经批准的慈善组织机构的捐赠能从您的增值税总收入中计入。
4 投资免税金融产品——韩国的一些金融产品,比如市政债券,免征某些税款。
5 借助税赋协定——如果您是与韩国签订税赋协定的国家的非居民或居民,您可能有资格享受减税或免税。
请务必注意,韩国的税法和法规非常复杂且经常变化,因此咨询税务专业人士以确定适合您个人情况的最佳策略可能会有所帮助。
已经非常靠谱了,居然连nisa这样的专业知识都知道。
已有的是学习资料:
关于chatgpt,只不过网上最常用的学习资料有如下两个:
关于instruct-gpt的论文,Training language models to follow instructions with human feedback李沐天神的对instruct-gpt的精读视频(其他还有gpt, gpt2, gpt3的精读视频),非常建议有时间的同学去看看:(我一开始看李沐天神的视频,总觉得他带上他们的面部视频,我看着有点不好原意,后来也是通心面了。。。)GPT,GPT-2,GPT-3 论文精读【论文精读】_哔哩哔哩_bilibiliInstructGPT 论文精读【论文精读·48】_哔哩哔哩_bilibili当然了,已经有很多博客和视频都在讲chatgpt了。出于好奇心,以及多年做chatbot的失败的经验,咱们也走一波学习。
怎么这么快?
抛开效果好的事实不谈,单单是chatgpt在采用的这时候的在线生成的速度,就让人觉得牛的一批。至少用了以下技术来加速:
nvidia triton或者openai他们家的类似triton的推理引擎;onnx;动态batch,dynamic batching。从原理上而言,chatgpt是基于transformer的decoder架构的,即是个“自回归”的模型,那是一个词一个词的来“蹦”出来了,而且前后词存在依赖关系,无法真正像“非自回归”模型那样来one-shot target sequence generation。
好吧,这里不免要带点私货,如果有特别想在一天之内实战搞定bert/gpt+onnx+triton+dynamic batching的从入门到部署(注意,是部署!没有部署的各种trick,chatgpt快不起来。。。)的课程,只不过最近在负责一个nvidia dli的课程(真心不贵,而且我们提供内嵌gpu,开箱即用):

这里面,从啥是transformer,到怎样基于bert来搞个分类,ner的模型,来微调,体能训练,调制tokenizer ,修改vocabulary,特别是到先期的改成onnx模型,借助tensorrt做优化,加trition做高并发推理,绝对的物超所值了。

当然,如果实在有想白嫖的,我估计三月底会录制几期视频,详细讲解呵呵。为啥是三月底呢,因为俺们厂的GTC 2023 (那个是纯免费的,能白嫖),是在2023年3月下旬,期间我会有上面的关于transformers 的dli的课程讲授。那个在线讲授之后,就能放开了说了【当然,会尽量照顾初学者】。
论文简介

这是一年前放出来的文章,2022年3月。
openai的特点是,工作具有一贯性,能说,除了CLIP(作者也是gpt1/gpt2的一作)的图片和文本是配对分类学习的,其他大部分都是基于transformer的decoder来搞事情--一招打天下。
之前被捧上天的bert,因为其masked language model的“不稳定性”,只不过在超大规模语言模型上(比如gpt3这种1750亿参数的),就没有bert什么事儿了。中小规模的模型,bert和其先期的数百种变种,都还有一些用。
真正到foundation models-基干模型(基础模型),还是需要transformer+生成式的单逻辑控制系统或者多逻辑控制系统任务。。。
摘要部分,主要是说:
大模型和用户没有align,(没有对齐),或者说,大模型(它酿的)不接用户那个“地气”!那你一次体能训练,花了上千万美刀,不是烧钱是啥?【这,是动机。估计是老板在骂:你们花这么多钱,啥这时候给厂里挣钱?别总搞格调和情怀,赶紧“落地”,“上线”,“挣小钱钱”!。。。也是那两个一作的国人,听懂了,“这pua套路,俺们熟悉啊”,然后就开始搞事情了。---这段纯属个人瞎写,千万别当真!】基于labeler-written prompts来微调【燃烧的是美刀】,既然没有align,那就align啊,fine-tune GPT3。这在之前是不敢想象的事情,居然发生了。。。1750亿参数,需要啥个TB的硬盘才能放下?怎样在gpu内存里面切割,都是挑战。当然,模型并行和数据并行是肯定的了。这块的用例能参考拙作:迷途小书僮:[细读经典]Megatron论文和代码详细分析(2) 简单一句话,是给gpt3,找了40个老师。【有啥人工,就有啥智能。。。从chatgpt的无所不能结果来看,这40个人立功了!】搞排序【那个是谷歌之流紧张的原因,排序。。。你能想到的包括但是不限于:竞价排名,广告点击排名,都是搜索啊。。。换谁谁不紧张?属于用真正有用的知识,抄了付费点击广告的后路了。。。之后谁还用keywords来搜索呢,所谓的seo,基于搜索引擎的网页优化,也会被真正的富知识网页或者多媒体内容给取代了。就拿个人最常用的谷歌地图而言,我跑步的这时候,想问的是“给我推荐一个走大道多的从A到B的路线”,或者“给我推荐一个风景秀丽的跑步路线”,“给我推荐一个阳光好的跑步路线”。。。单纯的谷歌地图就抓虾了。。。】这里是采用了基于人工反馈的强化学习(reinforcement learning from human feedback - RLHF),那个虽然不是研究上的新方法,但是做工程,可就太赞了,因为不单单是能基于厂内雇佣的labeler,所有的是chat gpt的用户,都是能提供positive/negative+reasons的反馈的。无所不能了。。。那个是杀手级别的。。。实时基于亿万用户的反馈来更新模型。。。想想就觉得兴奋。。。得到的instruct gpt模型只有1.3B(13亿参数),那个真实是吊炸天了。。。就没有见过13亿参数的模型,效果能有这么好的。。。估计上线的这时候,有不同的大小的。。。和new bing的时效性数据结合的话,比如新闻搜索,会有颠覆式的体验的。(期待着)。重点:
众包微调
fine-tuning with human feedbacks - 带有人工反馈的微调(众包微调)
瞬间觉得真正能改变世界的,是产品,不是一篇篇水文。。。
或者说,一篇篇水文,也是好的产品的重要的推动力(一草一木,一砖一瓦)。但是,如果局限在发paper上,难免格局小了。。。
之后,就摸着openai过河了。
看图理解细节
大段的文字,不容易说,直接上图吧。
图1,华山论剑
五大高手之间的比拼了:
【东邪西毒南帝北丐,中神通】
GPT,原始的gpt3的不同的规模的三个模型(最下面的一条线);GPT-prompted,加了提示的gpt3的三个模型;sft,给gpt加“有监督微调”,相当于说是执行了第一个阶段的人工干预。(40个人的1万多条标注数据的那个);PPO,用强化学习做多个候选的排序,第二阶段的人工干预(有人强化学习);PPO-ptx,用预体能训练的对数似然来规范(限制)PPO一把,别跑偏了。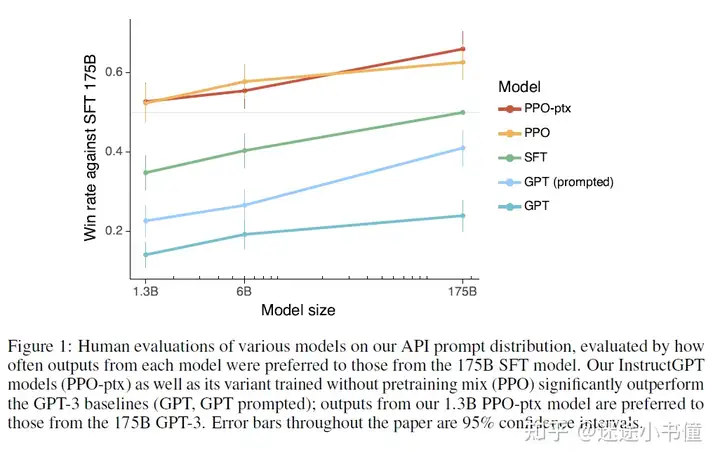
要看懂上图,需要搞清楚两个概念。
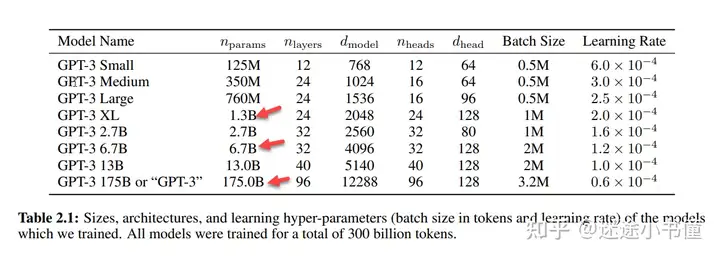
横轴:模型大小,从1.3B(13亿参数),到中间的6B(60亿参数),到后面的175B(即,gpt3的1750亿的参数)。
纵轴:战胜SFT(supervised fine-tuning,有监督微调) 175B模型的“胜率”。
那个SFT,需要记住,即基于40个人标注的1万多条数据,做有监督微调后的模型。比如SFT 175B,是微调gpt3了(乖乖。。。有钱真好。。。)。
proximal policy optimization (PPO),这是搞(第二阶段)强化学习的一个优化策略。
We can greatly reduce the performance regressions on these datasets by mixing PPO updates with updates that increase the log likelihood of the pretraining distribution (PPO-ptx), without compromising labeler preference scores.
上面这段文字,是解释PPO-ptx的,只不过觉得作者在藏着掖着了,单独看这句话,只不过不容易理解。。。
相当于说,把(1)强化学习PPO方法的对模型的更新,和(2)提升“预体能训练分布的对数似然”的对模型的更新,mix起来。
既要排序效果好(PPO强化学习管着呢),也不能距离原来的预体能训练任务的对数似然太远(对数似然管着呢)。
二合一的目标函数了。
回到那个图,说明了如下事情:
第一阶段人工干预下的sft gpt,是比原始的gpt,和带prompt提示的gpt好;第二阶段人工干预下的ppo, ppo-ptx是比第一阶段的sft,好。有人工干预,模型是能表现的更好!!走的是群众路线,赢!模型越大,人工调教效果越好。图2,葵花宝典
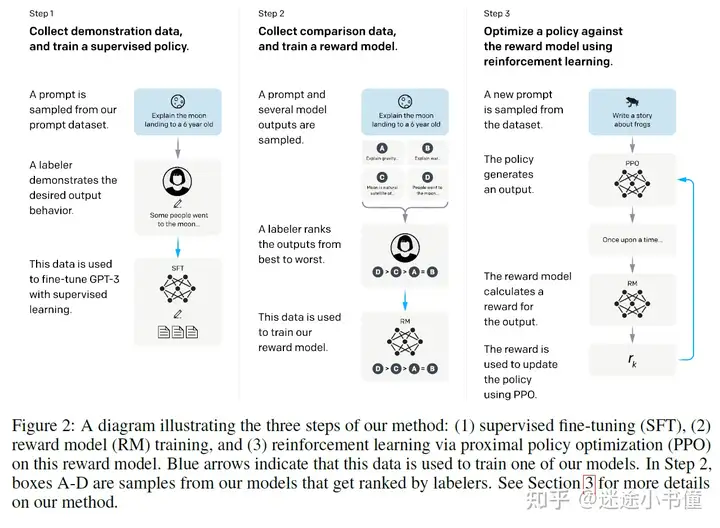
基本上搞懂了上面的那个图,就大概摸清了chatgpt的框架了。
葵花宝典第一式:欲练神功,必要人工(人工,人工,人工):
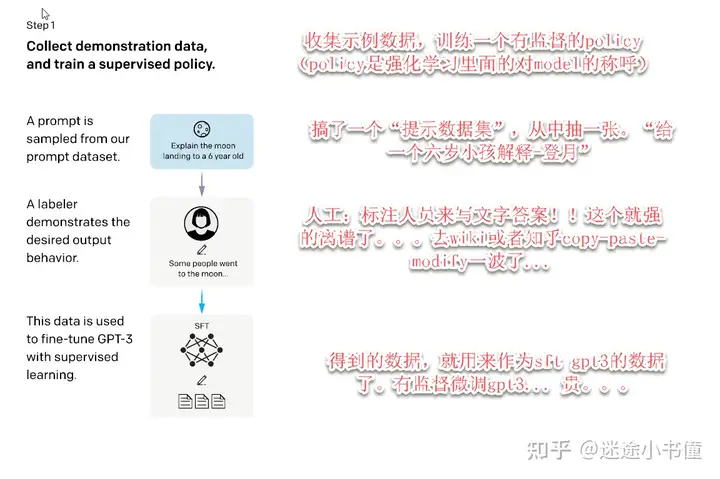
上面,是第一步:人工干预下的对gpt3的微调了。
sft gpt3,有监督微调gpt3,那个小数据,居然也能fine-tune得动gpt3。。。真实不可思议。。。那个很容易被小数据给带偏的。。。估计是作者在实现的这时候,先拿gpt3的小模型(gpt3论文里面一共用了八个不同大小的模型的!)尝试,然后逐步放大吧。。。
https://arxiv.org/pdf/2005.14165.pdf
葵花宝典第二式:排序人工,打赏靠盯:
上面是第二式了。关键是人工对gpt产出的结果排序,然后体能训练一个(learning-to-rank)的排序模型,从而通过pair-wise ranking来搞定对“打赏”模型的体能训练。
这块儿,只不过对搞搜索的人,再熟悉不过了。
估计之后,搜索引擎公司发力,抢占搜索入口,QA入口,也是指日可待了。
葵花宝典第三式:边练边赏,越学越通。【练赏循环,大巧不工】
上面是第三式的流程图。基于第二式的打赏模型,对policy(当前gpt3模型)打分,然后根据一大批“打赏”模型的产出,来更新policy模型。属于自洽闭环了。这里面的打赏模型,只不过是隐含了第三次人工标注:百万计的乐于反馈(正的负的都有)的“热心”用户!!一旦那个上线了,那必须是一往无前~~
表1/2,藏宝图
上面的表一,可就太重要了。
生成任务,接近一半了。说明啥,生成难,选择题很多人都会,但是无故写篇文章,写段文字,难!开放领域的问答,占据了12.4%,那个还是非常契合传统搜索引擎的query中的QA难题的占比的。基本上,搞定了问答,就能做个类似知乎这样的网络平台了。而传统搜索引擎,对已有的是碎片知识的整理,集成,是不如chatgpt这样的生成模型的。brainstorming,头脑风暴。那个个人体验了一把,很好,比如,我问chatgpt,我应该写哪些topics的文章,在什么领域灌水?怎么灌?它给我的提问,足够我忙一两年了。。。开心,感谢chatgpt。chat,那个是纯闲聊了吧。也有8.4%了,大概是天文地理,鸡毛蒜皮,家长里短了。之前做rinna和JAXP,最多的是闲聊。。。据说,讲故事的能力,决定了chatbot的闲聊的EQ上限。这块个人没啥兴趣。。。无非是(电子)精神榨菜了。rewrite,重写,6.6%,那个好。文章润色~~ 瞬间觉得给领导写报告有思路了。。。他们的周报也有主意了。嘿嘿。话说,谁能阻止我们基于chatgpt来给他们的论文润色挑错呢。。。太多惨不忍睹的grammer error, typo,也能很好的被chatgpt解决了,怪不得微软要“立刻马上”给office打包上那个。只不过留意过JAXP的两年前的打法,也是尝试和office榜呵呵,提高工作效率,提高办公生产力。。。summarization,那个对很多金融文章,能很好的抓headlines,搞垂直领域的摘要,一个方向的survey,就有搞头了。classification,那个居然也有。。。啥有些不理解了。你分类,找chatgpt,是要搞选择题吗。。。其他的长尾的。给chatgpt加上眼睛和耳朵,以及手脚,是一个趋势了。那个不多展开,免得被喷。公式们
打赏模型的损失函数
看看公式吧。抠呵呵细节。
上面是“打赏”模型的损失函数。期望拉大好的候选y_w和不好的候选y_l之间的距离。而x是输入的最初的prompt,提示文本串。
这里有个(K, 2),表示从K个元素里面,抽取两个,数量是K * (K-1) / 2了。
sigma是sigmoid函数,负责把两个“打分”映射到(0, 1)区间。然后取呵呵log,就能计算“期望值了”。
前面加负号,表示,最大化期望值。即让“打赏模型”尽量把好的候选(文本)和不好的候选,区分开。好的高分,不好的低分。
强化学习模型的损失函数:
上面的是基于PPO去优化的(最大化)目标函数,注意,被优化的参数集合是, \phi 。
而已有的是模型是SFT的那个。从公式上来看,SFT的policy在本轮强化学习的这时候,是”暂时“不变的。
x代表prompt,y代表模型(policy, 正在被学习的RL的gpt模型)产出的文本。
分别看呵呵:
其一,和预体能训练相关的:
上面的x是从D_pretrain,即预体能训练的分布中采样出来的。(或者说,拿原始的pretrained gpt,来给x打个”概率“的”分数“)。
其二,和打赏模型以及KL散度相关的:
prompt例子
后面是一系列具体的例子了。比如:
待续了。
下次详细分析论文中的例子。
没办法,每个人都在考虑怎样用chatgpt赚钱,俺也一样。。。
上一篇:满满干货(我害怕英语用英语怎么说)我害怕英语用英语怎么说写,我害怕chatgpt,因为它可能变得非常的危险,
栏 目:chatgpt安装
本文标题:不要告诉别人(抠一下是什么意思)抠chi,抠一下chatgpt的技术细节,
本文地址:http://www.shopify123.cn/chatgptanzhuang/3760.html
您可能感兴趣的文章
- 05-17居然可以这样(chatGPT中文网)ChatGPT中文免费破解版,chatgpt时代来了丨介绍丨小智AI,
- 05-16全程干货(wordpress 商品展示插件)wordpress做产品展示,wordpress网站对接chatgpt自动发布安装教程,
- 05-15居然可以这样(chatgpt国内能用吗)chatgpt怎么读,chatgpt如何搭建,
- 05-13太疯狂了(gpt3的文章生成器)gpt3中文自动生成小说,gpt3中文生成教程-chatgpt中文批量生成,
- 05-13难以置信(tracy 抖音)check it out check it out 抖音,chatgpt3中文生成模型原理-chatgpt中文生成教程,
- 05-11怎么可以错过(mongodb4.4.2安装教程)mongodb4.0安装教程,问chatgpt:在windows和ubuntu20.04上安装mongodb和进
- 05-11奔走相告(chatgpt中文)chatgpt app,chatgpt的计费方式和收费标准,一篇文章搞清楚,
- 05-10硬核推荐(如何制作一个爱)一图读懂如何制作,跟着chatgpt学习——如何制作出一个属于自己的AI,
- 05-06难以置信(如何训练自己的内心变得强大呢)怎样训练自己内心强大,如何训练自己的chatgpt模型,
- 05-06原创(ai人工智能英语翻译)关于ai智能的英语词汇有哪些,智能AI的时代已来临,号称中文版的chatgpt,试试?,


阅读排行
- 1居然可以这样(chatGPT中文网)ChatGPT中文免费破解版,chatgpt时代来了丨
- 2全程干货(wordpress 商品展示插件)wordpress做产品展示,wordpres
- 3居然可以这样(chatgpt国内能用吗)chatgpt怎么读,chatgpt如何搭建,
- 4太疯狂了(gpt3的文章生成器)gpt3中文自动生成小说,gpt3中文生成教程-chatg
- 5难以置信(tracy 抖音)check it out check it out 抖音,ch
- 6怎么可以错过(mongodb4.4.2安装教程)mongodb4.0安装教程,问chatg
- 7奔走相告(chatgpt中文)chatgpt app,chatgpt的计费方式和收费标准,
- 8硬核推荐(如何制作一个爱)一图读懂如何制作,跟着chatgpt学习——如何制作出一个属于自
- 9难以置信(如何训练自己的内心变得强大呢)怎样训练自己内心强大,如何训练自己的chatgpt
- 10原创(ai人工智能英语翻译)关于ai智能的英语词汇有哪些,智能AI的时代已来临,号称中文版
推荐教程
- 05-11奔走相告(chatgpt中文)chatgpt app,chatgpt的计费方式和收费标准,
- 05-17居然可以这样(chatGPT中文网)ChatGPT中文免费破解版,chatgpt时代来了丨
- 05-13太疯狂了(gpt3的文章生成器)gpt3中文自动生成小说,gpt3中文生成教程-chatg
- 04-23一篇读懂(qq怎么设置优雅的访问了别人的空间)怎么在qq引起他注意,如何优雅地在你的QQ中
- 04-23真没想到(中国为何没驻美大军)为什么中国没有美国驻军,为什么中国没有chatgpt #ai
- 04-21满满干货(怎么玩自己小豆视频)苹果手机怎么玩安卓游戏,国内怎么玩chatGPT?国产cha
- 04-22不看后悔(chatty app)chat tips,chatgpt推荐的装机方案,
- 04-23燃爆了(为什么中国没有参加世界杯)为什么中国没有健怡可乐,为什么中国没有chatgpt?,
- 04-21看完 chatgpt 写的声明,mini 公关真可下岗了 IBM 回应格芯起诉:这场诉讼毫
- 04-23不要告诉别人(chatbot和ChatGPT的区别)chatbot谁开发的,投资者提问:c